
Rationale and Objectives
To investigate consistency of the orders of performance levels when interpreting mammograms under three different reading paradigms.
Materials and Methods
We performed a retrospective observer study in which nine experienced radiologists rated an enriched set of mammography examinations that they personally had read in the clinic (“individualized”) mixed with a set that none of them had read in the clinic (“common set”). Examinations were interpreted under three different reading paradigms: binary using screening Breast Imaging Reporting and Data System (BI-RADS), receiver-operating characteristic (ROC), and free-response ROC (FROC). The performance in discriminating between cancer and noncancer findings under each of the paradigms was summarized using Youden’s index/2+0.5 (Binary), nonparameteric area under the ROC curve (AUC), and an overall FROC index (JAFROC-2). Pearson correlation coefficients were then computed to assess consistency in the ordering of observers’ performance levels. Statistical significance of the computed correlation coefficients was assessed using bootstrap confidence intervals obtained by resampling sets of examination-specific observations.
Results
All but one of the computed pair-wise correlation coefficients were larger than 0.66 and were significantly different from zero. The correlation between the overall performance measures under the Binary and ROC paradigms was the lowest (0.43) and was not significantly different from zero (95% confidence interval −0.078 to 0.733).
Conclusion
The use of different evaluation paradigms in the laboratory tends to lead to consistent ordering of the overall performance levels of observers. However, one should recognize that conceptually similar performance indexes resulting from different paradigms often measure different performance characteristics and thus disagreements are not only possible but frequently quite natural.
Considerable progress has been made in the last two decades with regard to our understanding of the methodologies needed for the analysis of retrospective observer performance studies ( ). Perhaps the simplest type of performance study is a binary detection task (binary response) that primarily provides performance measures in terms of sensitivity and specificity. Another frequently used approach is a receiver-operating characteristic (ROC) paradigm that provides information on how sensitivity and specificity change with varying decision thresholds for multicategory (discrete or semi-continuous) type ratings ( ). Another approach that has been recently gaining acceptance is the free-response ROC (FROC) paradigm, which uses a “locate then rate” approach with an a priori unknown number of suspected locations per image or examination ( ). The primary purpose of a specific study should determine which of the approaches is optimal in terms of validity, appropriateness, and clinical relevance ( ). Unfortunately, specific paradigms are frequently selected based on prior experience and/or expertise of the investigators, available resources, and prior studies performed to address the same or similar hypotheses.
Because the three paradigms can often be implemented in the same situation, an important question of interest is whether or not the results of a study performed under one paradigm (eg, ROC) are likely to remain had the study been performed under another paradigm (eg, FROC). Different observers may behave substantially differently under different paradigms, and there are virtually no data to support the consistency of radiologists’ performance levels when interpreting examinations under these different paradigms. It is a well known and studied phenomenon that radiologists’ interpretations vary substantially, leading to significant intra- and interobserver variabilities in general ( ) and during screening mammography interpretations in particular ( ). Thus, it is important to investigate whether the widely varying performance levels of readers under different paradigms correlate with each other.
Get Radiology Tree app to read full this article<
Get Radiology Tree app to read full this article<
Materials and methods
General Study Design
Get Radiology Tree app to read full this article<
Get Radiology Tree app to read full this article<
Get Radiology Tree app to read full this article<
Data Analyses
Get Radiology Tree app to read full this article<
Get Radiology Tree app to read full this article<
Get Radiology Tree app to read full this article<
Get Radiology Tree app to read full this article<
Get Radiology Tree app to read full this article<
Results
Get Radiology Tree app to read full this article<
Table 1
Binary, Receiver-operating Characteristic (ROC), and Free-response ROC (FROC) Performance Measures for Each of the Readers for the Combined set of “Common” and “Individualized” Examinations
Readers No. of Women without Verified Cancer No. of Women with Verified Cancer Actually Negative Breasts (without cancer) Actually Positive Breasts (with cancer) AUC-type Summary Indexes Under Different Paradigms Binary ROC FROC Total (= individualized + common) Total (= individualized + common) Total (= individualized + common) Total (= individualized + common) AUC ((Se+Sp)/2) JAFROC2 AUC (R = 20) (R = 30) (R = 40) 1 191 (= 100 + 91) 106 (= 42 + 64) 488 (= 242 + 246) 106 (= 42 + 64) 0.770 0.859 0.574 0.707 0.739 2 198 (= 107 + 91) 97 (= 33 + 64) 492 (= 246 + 246) 98 (= 34 + 64) 0.709 0.813 0.425 0.537 0.617 3 187 (= 96 + 91) 113 (= 49 + 64) 487 (= 241 + 246) 113 (= 49 + 64) 0.782 0.818 0.540 0.605 0.683 4 190 (= 99 + 91) 104 (= 40 + 64) 483 (= 237 + 246) 105 (= 41 + 64) 0.807 0.805 0.538 0.659 0.723 5 188 (= 97 + 91) 108 (= 44 + 64) 484 (= 238 + 246) 108 (= 44 + 64) 0.768 0.865 0.598 0.675 0.746 6 194 (= 103 + 91) 82 (= 18 + 64) 470 (= 224 + 246) 82 (= 18 + 64) 0.740 0.729 0.444 0.544 0.591 7 187 (= 96 + 91) 88 (= 24 + 64) 462 (= 216 + 246) 88 (= 24 + 64) 0.790 0.842 0.549 0.639 0.724 8 199 (= 108 + 91) 78 (= 14 + 64) 476 (= 230 + 246) 78 (= 14 + 64) 0.748 0.797 0.557 0.649 0.692 9 207 (= 116 + 91) 90 (= 26 + 64) 504 (= 258 + 246) 90 (= 26 + 64) 0.812 0.854 0.560 0.686 0.740 Average 0.770 0.820 0.532 0.633 0.695
AUC, area under the curve; JAFROC, jackknife free-response receiver-operating characteristic; Se, sensitivity; Sp, specificity.
Get Radiology Tree app to read full this article<
Get Radiology Tree app to read full this article<
Table 2
Computed Pearson Correlation Coefficients for All Readers Using Overall Performance Measures Computed for Ratings Under the Different Paradigms
Scales of Pairwise Correlated Measures Pearson Correlation Coefficient First Scale Second Scale Estimate 95% Bootstrap Confidence Interval Binary ROC 0.430 −0.078, 0.733 FROC (R = 20) 0.667 0.184, 0.836 FROC (R = 30) 0.694 0.235, 0.841 FROC (R = 40) 0.750 0.262, 0.890 ROC FROC (R = 20) 0.711 0.275, 0.875 FROC (R = 30) 0.726 0.345, 0.877 FROC (R = 40) 0.834 0.485, 0.928 FROC (R = 20) FROC (R = 30) 0.924 0.741, 0.967 FROC (R = 40) 0.935 0.703, 0.969 FROC (R = 30) FROC (R = 40) 0.951 0.827, 0.977
FROC, free-response receiver-operating characteristic; ROC, receiver-operating characteristic.
Get Radiology Tree app to read full this article<
Discussion
Get Radiology Tree app to read full this article<
Get Radiology Tree app to read full this article<
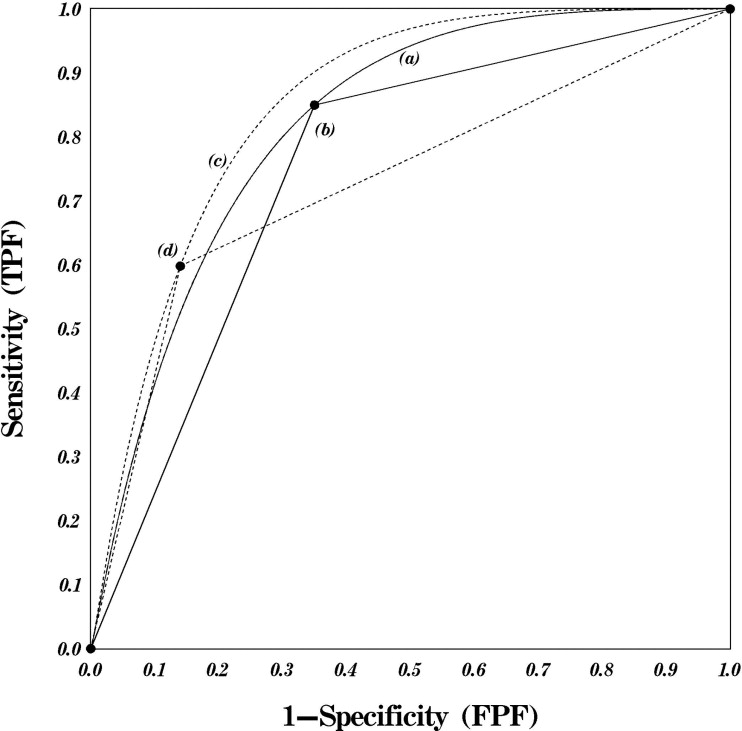
Get Radiology Tree app to read full this article<
Get Radiology Tree app to read full this article<
Get Radiology Tree app to read full this article<
Get Radiology Tree app to read full this article<
Get Radiology Tree app to read full this article<
Get Radiology Tree app to read full this article<
References
1. DeLong E.R., DeLong D.M., Clarke-Pearson D.L.: Comparing the area under two or more correlated receiver operating characteristic curves: a nonparametric approach. Biometrics 1988; 44: pp. 837-845.
2. Dorfman D.D., Berbaum K.S., Metz C.E.: Receiver operating characteristic rating analysis. Invest Radiol 1992; 27: pp. 723-731.
3. Obuchowski N.A., Rockette H.E.: Hypothesis testing of the diagnostic accuracy for multiple diagnostic tests: an ANOVA approach with dependent observations. Communications Statistics Simulations Computations 1995; 24: pp. 285-308.
4. Beiden S.V., Wagner R.F., Campbell G.: Components of variance models and multiple bootstrap experiments: an alternative method for random effects, receiver operating characteristics analysis. Acad Radiol 2000; 7: pp. 341-349.
5. Ishwaran H., Gatsonis C.A.: A general class of hierarchical ordinal regression models with applications to correlated ROC analysis. Can J Statistics 2000; 28: pp. 731-750.
6. Wagner R.F., Beiden S.V., Campbell G., Metz C.E., Sacks W.M.: Assessment of medical imaging and computer-assist systems: lessons from recent experience. Acad Radiol 2002; 9: pp. 1264-1277.
7. Obuchowski N.A., Beiden S.V., Berbaum K.S., et. al.: Multireader, multicase receiver operating characteristic analysis: an empirical comparison of five methods. Acad Radiol 2004; 11: pp. 980-995.
8. Bandos A.I., Rockette H.E., Gur D.: A permutation test for comparing ROC curves in multireader studies. Acad Radiol 2006; 13: pp. 414-420.
9. Gallas B.: One-shot estimate of MRMC variance: AUC. Acad Radiol 2006; 13: pp. 353-362.
10. Bandos A.I., Rockette H.E., Gur D.: Exact bootstrap variances of the area under the ROC curve. Commun Statistics—Theory & Methods 2007; 36: pp. 2443-2461.
11. Gur D., Rockette H.E., Armfield D.R., et. al.: Prevalence effect in a laboratory environment. Radiology 2003; 228: pp. 10-14.
12. Shah S.K., McNitt-Gray M.F., De Zoysa K.R., et. al.: Solitary pulmonary nodule diagnosis on CT: results of an observer study. Acad Radiol 2005; 12: pp. 496-501.
13. Skaane P., Balleyguier C., Diekmann F., et. al.: Breast lesion detection and classification: comparison of screen-film mammography and full-field digital mammography with soft-copy reading—observer performance study. Radiology 2005; 237: pp. 37-44.
14. Shiraishi J., Abe H., Li F., Engelmann R., MacMahon H., Doi K.: Computer-aided diagnosis for the detection and classification of lung cancers on chest radiographs ROC analysis of radiologists’ performance. Acad Radiol 2006; 13: pp. 995-1003.
15. Wagner R.F., Metz C.E., Campbell G.: Assessment of medical imaging systems and computer aids: a tutorial review. Acad Radiol 2007; 14: pp. 723-748.
16. Zheng B., Chakraborty D.P., Rockette H.E., Maitz G.S., Gur D.: A comparison of two data analyses from two observer performance studies using Jackknife ROC and JAFROC. Med Phys 2005; 32: pp. 1031-1034.
17. Gur D., Rockette H.E., Bandos A.I.: “Binary” and “non-binary” detection tasks: are current performance measures optimal?. Acad Radiol 2007; 14: pp. 871-876.
18. Wagner R.F., Beiden S.V., Metz C.E.: Continuous versus categorical data for ROC analysis: some quantitative considerations. Acad Radiol 2001; 8: pp. 328-334.
19. Metz C.E., Shen J.H.: Gains in accuracy from replicated readings of diagnostic images: prediction and assessment in terms of ROC analysis. Med Decis Making 1992; 12: pp. 60-75.
20. Swensson R.G., King J.L., Good W.F., Gur D.: Observer variation and the performance accuracy gained by averaging ratings of abnormality. Med Phys 2000; 27: pp. 1920-1933.
21. Elmore J.G., Wells C.K., Lee C.H., Howard D.H., Feinstein A.R.: Variability in radiologists’ interpretations of mammograms. N Engl J Med 1994; 331: pp. 1493-1499.
22. Beam C.A., Layde P.M., Sullivan D.C.: Variability in the interpretation of screening mammograms by US radiologists. Arch Intern Med 1996; 156: pp. 209-213.
23. Elmore J.G., Wells C.K., Howard D.H.: Does diagnostic accuracy in mammography depend on radiologists’ experience?. J Women’s Health 1998; 7: pp. 443-449.
24. Esserman L., Cowley H., Eberle C., et. al.: Improving the accuracy of mammography: volume and outcome relationships. J Natl Cancer Inst 2002; 94: pp. 369-375.
25. Beam C.A., Conant E.F., Sickles E.A.: Association of volume and volume-independent factors with accuracy in screening mammogram interpretation. J Natl Cancer Inst 2003; 95: pp. 282-290.
26. Beam C.A., Conant E.F., Sickles E.A.: Factors affecting radiologists inconsistency in screening mammography. Acad Radiol 2002; 9: pp. 531-540.
27. Eng J.: Receiver operating characteristic analysis: a primer. Acad Radiol 2005; 12: pp. 909-916.
28. Berbaum K.S., Dorfman D.D., Franken E.A., Caldwell R.T.: An empirical comparison of discrete ratings and subjective probability ratings. Acad Radiol 2002; 9: pp. 756-763.
29. Rockette H.E., Gur D., Metz C.E.: The use of continuous and discrete confidence judgments in receiver operating characteristic studies of diagnostic imaging techniques. Investig Radiol 1992; 27: pp. 169-172.
30. Gur D, Bandos AI, King JL, et al. Binary and multi-category ratings in a laboratory observer performance study: a comparison. Med Phys, in press.
31. Hilden J.: Regret graphs, diagnostic uncertainty and Youden’s index. Statistics in Medicine 1996; 15: pp. 969-986.
32. Hanley J.A., McNeil B.J.: The meaning and use of the area under receiver operating characteristic (ROC) curve. Radiology 1982; 143: pp. 29-36.
33. Chakraborty D.P., Berbaum K.S.: Observer studies involving detection and localization: modeling, analysis, and validation. Med Phys 2004; 31: pp. 2313-2330.
34. Gur D., Bandos A.I., Cohen C.S., et. al.: The “laboratory” effect: comparing radiologists’ performance and variability during clinical prospective and laboratory mammography interpretations. Radiology 2008; Aug 5, epub ahead of print
35. American College of Radiology (ACR): Breast imaging reporting and data system atlas (BI-RADS atlas).2003.American College of RadiologyReston (VA) http://www.acr.org/SecondaryMainMenuCategories/quality_safety/BIRADSAtlas.aspx Accessed October 1, 2003
36. Youden W.J.: An index for rating diagnostic tests. Cancer 1950; 3: pp. 32-35.
37. Chakraborty D., Yoon H.J., Mello-Thoms C.: Spatial localization accuracy of radiologists in free-response studies: inferring perceptual FROC curves from mark-rating data. Acad Radiol 2007; 14: pp. 4-18.