
Rationale and Objectives
New tests are typically assessed by estimating their technical and diagnostic performance through comparisons with a reference standard. A valid reference standard, however, is not always available and is not required for assessing the interchangeability of a new test with an existing one.
Materials and Methods
To show interchangeability of a new test with an existing test, one compares the differences in diagnoses between the new and existing tests to differences between diagnoses made with the existing test on several occasions. We illustrate the test for interchangeability with two studies. In a transcatheter aortic valve replacement study, we test whether semiautomated analysis can be used interchangeably with manual reconstructions from three-dimensional computed tomography (CT) images. In patients with femoroacetabular impingement, we test whether magnetic resonance imaging (MRI) can replace CT to measure acetabular version.
Results
Although the semiautomated method agreed often with the manual measurement of aortic valve size (87.6%), interchanging the semiautomated method with manual measurements by an expert would lead to a 1.7%–12.2% increase in the frequency of disagreement. Interchanging MRI for CT to measure acetabular version would lead to differences in angle measurements of 2.0° to 3.1° in excess of the differences we would expect to see with CT alone.
Conclusions
Testing for agreement or correlation between a new and an existing test is not sufficient evidence of the performance of a new test. A formal evaluation of interchangeability can be conducted in the absence of a reference standard.
As new medical imaging tests and procedures are developed, it is imperative that their performance be assessed before the new test can be used in clinical practice. The intended use of the new test affects how it is assessed. If the new test is to be used as an adjunct to the existing test, then its performance in combination with the existing test should be superior to the performance of the existing test alone. If the new test is to replace the existing test, then its performance as a stand alone should not be inferior to the existing test. Another role for new tests is interchangeability with an existing test. Here, we assess whether the new test can be switched with the existing test without affecting individual patients’ diagnoses.
For adjunct and replacement roles, new tests are assessed by estimating their technical and diagnostic performance through comparisons with a gold or reference standard (eg, sensitivity, specificity, and receiver operating characteristic (ROC) analysis) . We compare the performance (eg area under the ROC curve) of the new and existing tests for the relevant population of patients . A valid reference standard, however, is not always available and is not required for assessing interchangeability. When interchanging a new test with an existing test, we must have sufficient evidence that for individual patients , either of the tests can be used with similar results. Replacement is a less burdensome criterion than interchangeability because the test results of individual patients do not need to agree, only the performance over the population of patients.
Get Radiology Tree app to read full this article<
Get Radiology Tree app to read full this article<
Get Radiology Tree app to read full this article<
Methods
Test for Interchangeability
Get Radiology Tree app to read full this article<
Get Radiology Tree app to read full this article<
H0:γ=E(YiTjk−YiRjk’)2–E(YiRjk−YiRjk’)2>θIversusH1:γ≤θI H
0
:
γ
=
E
(
Y
i
T
j
k
−
Y
i
R
j
k
’
)
2
–
E
(
Y
i
R
j
k
−
Y
i
R
j
k
’
)
2
θ
Ι
versus
H
1
:
γ
≤
θ
I
where γ γ is the individual equivalence index and θI θ
Ι is the equivalence limit. θI θ
Ι would be defined during the planning phase of a study. It can be shown that the individual equivalence criterion in Equation ( 1 ) is equivalent to the squared difference in the means of the two modalities plus the difference in their variances:
γ=(μT−μR)2+σ2T−σ2R, γ
=
(
μ
T
−
μ
R
)
2
+
σ
T
2
−
σ
R
2
,
where μ T and σ2T σ
T
2 are the mean and variance of the measurements on the new test modality, respectively, and μ R and σ2R σ
R
2 are the mean and variance of the measurements on the reference modality, respectively. Note that if the new test modality has little bias (ie, μT≅μR μ
T
≅
μ
R ), it can have a little less precision ( σ2T>σ2R σ
T
2
σ
R
2 ) and still be considered interchangeable with the reference test, or if the new test modality is more precise than the reference test ( σ2T<σ2R σ
T
2
<
σ
R
2 ), it can have a little bias (ie, μT≠μR μ
T
≠
μ
R ) and still be considered interchangeable.
Get Radiology Tree app to read full this article<
Get Radiology Tree app to read full this article<
Get Radiology Tree app to read full this article<
H0:γ(p)=Prob(YiRjk=YiRjk’)–Prob(YiTjk=YiRjk)>θI(p)versusH1:γ(p)≤θI(p) H
0
:
γ
(
p
)
=
P
r
o
b
(
Y
i
R
j
k
=
Y
i
R
j
k
’
)
–
P
r
o
b
(
Y
i
T
j
k
=
Y
i
R
j
k
)
θ
Ι
(
p
)
versus
H
1
:
γ
(
p
)
≤
θ
I
(
p
)
where Prob(YiRjk=YiRjk’) P
r
o
b
(
Y
i
R
j
k
=
Y
i
R
j
k
’
) is the probability that the result (eg, valve size) determined at two occasions (eg, two readers j and j’ j
’ ) with the reference test agree for subject i , and Prob(YiTjk=YiRjk) P
r
o
b
(
Y
i
T
j
k
=
Y
i
R
j
k
) is the probability that the results of the new and reference tests agree for subject i .
Get Radiology Tree app to read full this article<
Get Radiology Tree app to read full this article<
TAVR Study
Get Radiology Tree app to read full this article<
Get Radiology Tree app to read full this article<
Get Radiology Tree app to read full this article<
Get Radiology Tree app to read full this article<
Get Radiology Tree app to read full this article<
The Same-Reader Scenario
Get Radiology Tree app to read full this article<
γˆ(p)=∑Ni=1πR,RN–∑Ni=1∑2k=1∑2k’=1πT,R4N, γ
ˆ
(
p
)
=
∑
i
=
1
N
π
R
,
R
N
–
∑
i
=
1
N
∑
k
=
1
2
∑
k
’
=
1
2
π
T
,
R
4
N
,
where π__R,R equals 1 when the manual measurements made by the expert reader on two occasions lead to the same valve size (ie, Y__iR 11 = Y__iR 12 ) and 0 otherwise. Similarly, π__R,T equals 1 when the manual and semiautomated measurements made by the expert reader lead to the same valve size (ie, YiR1k Y
i
R
1
k = YiT1k’ Y
i
T
1
k
’ ) and 0 otherwise.
Get Radiology Tree app to read full this article<
Different-Reader Scenario
Get Radiology Tree app to read full this article<
γˆ(p)=∑Ni=1∑2k=1πR,R2N–∑Ni=1∑2k′=1∑2k=1πT,R4N, γ
ˆ
(
p
)
=
∑
i
=
1
N
∑
k
=
1
2
π
R
,
R
2
N
–
∑
i
=
1
N
∑
k
’
=
1
2
∑
k
=
1
2
π
T
,
R
4
N
,
where π__R,R equals 1 when two manual measurements made by the readers lead to the same valve size (ie, Y__iR 1 k = Y__iR 21 ) and 0 otherwise. Similarly, π__R,T equals 1 when manual and semiautomated measurements made by readers lead to the same valve size (ie, YiR1k Y
i
R
1
k = YiT2k’ Y
i
T
2
k
’ ) and 0 otherwise.
Get Radiology Tree app to read full this article<
Get Radiology Tree app to read full this article<
Acetabular Version Study
Get Radiology Tree app to read full this article<
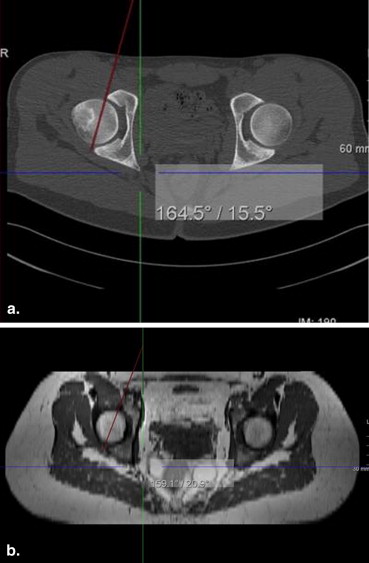
Get Radiology Tree app to read full this article<
Get Radiology Tree app to read full this article<
Random-Reader Scenario
Get Radiology Tree app to read full this article<
γˆ=∑Jj=1∑Jj=1∑Mi=1∑2k=1∑2k′=1(YiTjk–YiRj’k′)24MJ2−∑Jj=1∑Jj=1∑Mi=1∑2k=1∑2k′=1(YiRjk–YiRj’k′)24MJ2, γ
ˆ
=
∑
j
=
1
J
∑
j
=
1
J
∑
i
=
1
M
∑
k
=
1
2
∑
k
’
=
1
2
(
Y
i
T
j
k
–
Y
i
R
j
’
k
’
)
2
4
M
J
2
−
∑
j
=
1
J
∑
j
=
1
J
∑
i
=
1
M
∑
k
=
1
2
∑
k
’
=
1
2
(
Y
i
R
j
k
–
Y
i
R
j
’
k
’
)
2
4
M
J
2
,
where J = 3 readers and M = 22 hips.
Get Radiology Tree app to read full this article<
Get Radiology Tree app to read full this article<
Results
TAVR Study
Get Radiology Tree app to read full this article<
Table 1
Data for Interchangeability Test Under the Same-Reader Scenario
Valve Size From Two Manual Measurements Valve Size From the First Manual and the First Automated Valve Size From the First Manual and Second Automated Valve Size From Second Manual and the First Automated Valve Size From Second Manual and Second Automated Agree No Agree No Agree No Agree No Agree 92 11 93 10 91 12 93 10 No Agree 2 4 1 5 5 1 5 1
Get Radiology Tree app to read full this article<
Get Radiology Tree app to read full this article<
Get Radiology Tree app to read full this article<
Acetabular Version Example
Get Radiology Tree app to read full this article<
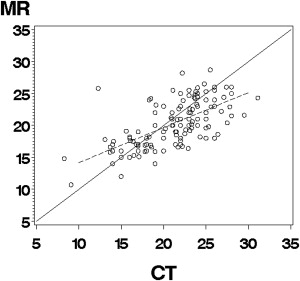
Get Radiology Tree app to read full this article<
Get Radiology Tree app to read full this article<
Conclusions
Get Radiology Tree app to read full this article<
Table 2
Comparison of Replacement and Interchangeability Studies
Replacement or Adjunct Interchangeability Study design Reference standard/ground truth Yes No Repeat measurements No Yes Performance metrics Bias, accuracy Agreement in test results Unit of analysis Study sample Individual patients Hypothesis Superiority or noninferiority of accuracy Noninferiority of agreement
Get Radiology Tree app to read full this article<
Get Radiology Tree app to read full this article<
Get Radiology Tree app to read full this article<
Get Radiology Tree app to read full this article<
Get Radiology Tree app to read full this article<
Appendix
Get Radiology Tree app to read full this article<
Get Radiology Tree app to read full this article<
References
1. Zhou X.H., Obuchowski N.A., McClish D.L.: Statistical methods in diagnostic medicine.2011.Wiley and Sons, Inc.New York
2. Pepe M.S.: The statistical evaluation of medical tests for classification and prediction.2003.Oxford University PressNew York, NY
3. Zou K.H., Liu A., Bandos A.I., et. al.: Statistical evaluation of diagnostic performance: topics in ROC analysis.2012.Chapman and Hall/CRC Biostatistics SeriesBoca Raton, FL
4. Lou J, Obuchowski NA, Krishnaswamy A, Popovic Z, Flamm SD, Kapadia SR, Svensson L, Bolen M, Desai MY, Halliburton SS, Tuzcu EM, Schoenhagen P. Semi-automated versus manual aortic annulus analysis for planning of transcatheter aortic valve replacement (TAVR/TAVI). Submitted.
5. Anderson S., Hauck W.W.: Consideration of individual bioequivalence. J Pharmacokinet Biopharm 1990; 18: pp. 259-273.
6. Schall R., Luus H.G.: On population and individual bioequivalence. Stat Med 1993; 12: pp. 1109-1124.
7. Chou S.C., Yang L.Y., Starr A., et. al.: Statistical methods for assessing interchangeability of biosimilars. Stat Med 2013; 32: pp. 442-448.
8. Chou S.C.: Assessing biosimilarity and interchangeability of biosimilar products. Stat Med 2013; 32: pp. 361-363.
9. www.fda.gov/drugs/developmentapprovalprocess/howdrugsaredevelopedandapproved/approvalapplications/therapeuticbiologicapplications/biosimilars .
10. Obuchowski N.A.: Can electronic medical images replace hard-copy film? Defining and testing the equivalence of diagnostic tests. Stat Med 2001; 20: pp. 2845-2863.
11. Barnhart H.X., Kosinski A.S., Haber M.J.: Assessing individual agreement. J Biopharm Stat 2007; 17: pp. 697-719.
12. Hardin J., Hilbe J.: Generalized estimating equations.2003.Chapman and Hall/CRCLondon
13. Subhas unpublished work.
14. Cohen J.: Weighed kappa: nominal scale agreement with provision for scaled disagreement or partial credit. Psychol Bull 1968; 70: pp. 213-220.